


1000+ new domain endings (nTLDs) have been released since 2014. Some of them – the GEOs – are explicitly about location: for instance, .LONDON, .NYC, and .IRISH. Most, though, are generic keywords like .CLUB, .FISH, .NINJA, or .ONLINE, which are not rooted in 1 place.
While some nTLDs are registered at a uniform rate in every country, others skew strongly toward certain nations. Last time, I calculated this “skew” for each of 4,920 country / nTLD pairs. Please refer to the table.
Skew answers various questions: How strong is the predilection for .IRISH in Ireland compared to the rest of the planet? Among Germany, Switzerland, Austria, which country is most biased toward .KAUFEN? How pronounced is China’s emphasis of .XYZ compared to .WANG or .世界?
It’s important to understand that Skew doesn’t measure local popularity in an absolute sense. For instance, .TOP tops the list in Ireland, where .IRISH ranks only #2 even in the emerald isle itself. Rather, what Skew measures is local deviation from the world at large. Thus, a #2 ranking for .IRISH is a big departure from the norm (Skew = 1014.7). Surprisingly, despite a #1 ranking, .TOP is registered in Ireland at less than the average global rate (Skew = 0.75). Basically, Skew measures local idiosyncrasy, not local popularity.
At the farthest extreme, we see cases like .IRISH in Ireland or .CAPETOWN in South Africa, where Country and TLD occur together at Skew = 1000 times the worldwide average. When Skew = 1, Country and TLD coincide in a way that mirrors the planet overall. And when Skew is less than 1, we know that – even if the country has registered many domains in the TLD – this pairing shows up at less than the global rate.
What causes skew? Every pair of country + nTLD has its own story. But certain general factors play a big role. GEOs are a special case, first of all. Obviously, .BERLIN registrations will spike in Germany; .AMSTERDAM will skew toward the Netherlands; and Japan will show strong bias toward .TOKYO.
That’s a safe hypothesis. Now let’s quantify reality:
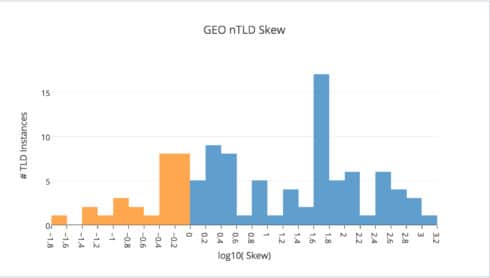
Don’t be intimidated by the histogram above. The horizontal axis is just Skew – the same numbers you saw in last week’s table. We’re counting the number of Country / nTLD pairs that occur disproportionately together. Why the logarithmic scale? To make the data viewable. Skew ranges as high as 1000+ and as low as 0.001. Big values need to be squished; so the blue part (Skew from 1 to 1000+) is shown from 0 to 3+. Small values need to be elongated; so the orange part (Skew from 0.001 to 1) is shown from -3 to 0. Don’t worry if you’ve forgotten how logarithms work. Here’s all you need to know:
| Skew | 0.001 | 0.01 | 0.1 | 1.0 | 10 | 100 | 1000 |
| Log10(Skew) | -3 | -2 | -1 | 0 | 1 | 2 | 3 |
As you can see, Ireland / .IRISH has Skew = 1014.7 = 103.01; so it’s at the far right. Meanwhile, Mexico / .LAT, which has Skew = 615.3 = 102.79, is 1 of 4 Country / nTLD pairs counted with log10(Skew) between 2.6 and 2.8. The blue region represents all cases where Skew ≥ 1.0 – that is to say, all instances of positive nTLD / bias.
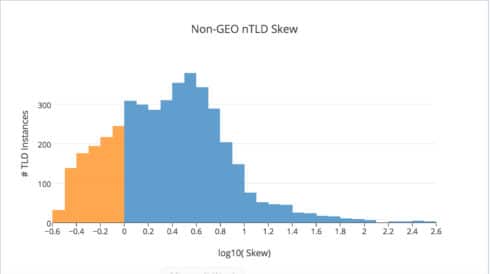
Compare the first histogram (which represents GEO nTLDs) to the plot above (which shows non-GEOs). Relatively few non-GEO suffixes have log10(Skew) > 1. In other words, the vast majority of have Skew < 10. So if a non-GEO nTLD is overrepresented in some country, it’s likely to be found with a disproportion below a factor of 10. In contrast, GEO nTLD / country pairs deviate from the global average much more intensely. Roughly half the plot’s total area is found with log10(Skew) between 1 and 3.2. That means GEOs that rank in country charts will be overrepresented there by a factor of 10 – 1000 about 50% of the time.
In the next article, we’ll delve deeper into language.

Leave a Comment